
binjgb rewind
I stopped working on binjgb, and blogging, and other personal projects earlier this year. It's a lot of work! And when the weather gets nice, it's hard to stay inside and hack...
But in late June I picked up binjgb a bit and started working on a new feature: rewinding.
I was inspired by a reddit post announcing a new NES emulator called nintaco. It actually has quite a few cool features, but the one that got the most attention was the ability to "rewind time".
The top question in the reddit comments asks, how does it work? The answer:
It records controller input and it captures a save state at a fixed interval. For random access, it restores the nearest save state and then it uses the input sequence to fill in the gap. You can play for quite a few hours before filling up memory.
It's a simple, straightforward solution, and it works well. I love when that happens!
It makes sense too: since the emulation is deterministic, as long as we record all sources of non-determinism we can fully recreate the emulation state at any point in time in the past.
Step 0: Save State
I actually had already implemented save state functionality. I wrote binjgb in
C, and was very careful to keep all state in just one 51KiB struct,
EmulatorState. As a result, saving the state of the emulator was as simple as
writing the contents of that struct to a file.
Result emulator_write_state(Emulator* e, FileData* file_data) {
CHECK(file_data->size >= sizeof(EmulatorState));
e->state.header = SAVE_STATE_HEADER;
memcpy(file_data->data, &e->state, file_data->size);
return OK;
ON_ERROR_RETURN;
}This has some caveats, of course. The save states are not necessarily compatible between different versions of binjgb, or even the same version of binjgb compiled with different C compilers. But in general it works, and it is very simple and efficient.
Step 1: Save Joypad Input
The gameboy, like the NES, doesn't have much to save for joypad input. There are just 4 buttons (A, B, Start, Select), and 4 directional inputs, for a total of 8 bits.
You could store this info once per frame and never notice the memory usage. The gameboy runs at ~59.7 frames/second, which means that at 1 byte/frame, I would use 60b/sec = 3.5KiB/min = 84KiB/hour = 5MiB/day. But I didn't do it this way.
binjgb actually uses a callback to ask what the current input state is whenever the emulated gameboy would. This can happen at any time during a frame, and often happens multiple times. This means that the values could change over the course of a frame, so I actually want cycle granularity for inputs.
Since the gameboy runs at ~4MHz, I probably shouldn't store the input for each cycle (4MiB/sec = 240MiB/min = 14GiB/hour.)
Instead, I rely on the fact that the input rarely changes and just store the new input whenever it does, along with when it happened. In binjgb, the cycle count is stored as a 64-bit value. Adding 1 byte for the input (and padding) gives 12 bytes per entry. It would be simple enough to use a dynamic array for this, but for no particular reason I decided to use a doubly-linked list of fixed buffers instead.
typedef struct {
Cycles cycles;
u8 buttons;
u8 padding[3];
} JoypadState;
typedef struct JoypadBuffer {
JoypadState* data;
size_t size;
size_t capacity;
struct JoypadBuffer *next, *prev;
} JoypadBuffer;Just to give you an idea, after playing through the first four levels of Super Mario Land (in about 4 minutes -- a speedrunner I am not) this uses about 12.5KiB. This gives me memory usage rates in the same ballpark as before when storing just one byte per frame.
Step 2: Continuously Save States
So the simple, straightforward idea above was to save emulator state at a fixed interval. But as I did the calculations, it left me a bit unsatisfied. Since the save state is 51KiB, that means that if I saved the state every frame, it would require 3MiB/sec = 175MiB/min = 10GiB/hour.
It seemed I could improve this a few ways: saving the state less often, or compressing the state so it is smaller, or both.
Step 2.1: Save State Less Often
Even though rewinding doesn't need to be realtime, I really wanted to keep it realtime if I could. If I save state less often, then the only way to make that work is to simulate more. I haven't spent too much time optimizing it, but binjgb is pretty fast, even in debug mode. Running the simulation without any graphics yields a framerate of about 600fps with debugging information. That's measuring gameboy frames. Since I want to rewind at 60fps, that means I can simulate at about 10gbfpf: 10 gameboy frames per frame.
So if I save states 1/10th as often, then it would only be 300KiB/sec. Pretty good, but I wanted to do better.
Step 2.2: Compress Save States
I could have just used zlib and been done with it, but I've been trying to keep the number of dependencies to a minimum, so I wondered if there was another way.
The save state is 51KiB, but what is actually saved? It turns out that most of
this (32KiB) is used for EXT RAM, i.e. battery-backed RAM. 32KiB is the maximum
size, and even though most carts don't use that much, having a fixed-size
buffer is convenient for keeping the save state simple. If the buffer were
variable-size, it would have to be a allocated, which means it would be stored
as a pointer, which means I can't memcpy it to a file.
What this means is that the 32KiB state is mostly zero, same with the 8KiB of work RAM. Given that, a simple Run Length Encoding (RLE) scheme should work well. As an experiment, I had binjgb save the emulator state once per frame to a set of files, and did some analysis.
Step 2.3: RLE
There are a many different ways you can do RLE encoding, so I tried a couple them with the extracted save states. They all use the same basic idea: find runs of the same number in the input stream and compress them to a pair of the number and the length of the run.
def FindRuns(s):
last = -1
start = 0
in_run = None
for i, x in enumerate(s):
match = x == last
if match != in_run:
if in_run is not None:
if in_run:
yield ('run', i - start + 1, last)
elif i - 1 > start:
yield ('norun', s[start:i-1])
in_run = match
start = i
if not match:
last = x
i += 1
if in_run:
yield ('run', i - start + 1, last)
elif i > start:
yield ('norun', s[start:i])Not the most elegant code, but it is fine for a prototype. This function will
take the input and yield tuples a tuples of either ('run', length, value) or
('norun', [value0, value1, ...]).
The simplest way to encode RLE is to just store length value pairs, using a
length of 1 for each value that isn't in a run.
def RLE1(s):
data = []
for r in FindRuns(s):
if r[0] == 'run':
count, value = r[1:]
while count > 255:
data.extend([255, value])
count -= 255
data.extend([count, value])
else:
for x in r[1]:
data.extend([1, x])
return bytearray(data)
# input: 1 2 3 4 4 4 4 4 1 1 2 3
# output: 1 1 1 2 1 3 5 4 2 1 1 2 1 3But this method of doing RLE is inefficient with non-runs. Instead, there is a
common trick that saves space: non-run values are stored directly in the output
stream, and runs are stored by storing the same value twice, then following
that with the remaining length. So a run of 5s with length 10 would be stored
as 5 5 8.
def RLE2(s):
data = []
for r in FindRuns(s):
if r[0] == 'run':
count, value = r[1:]
while count > 257:
data.extend([value, value, 255])
count -= 257
if count >= 2:
count -= 2
data.extend([value, value, count])
elif count == 1:
data.append(value)
else:
data.extend(r[1])
return bytearray(data)
# input: 1 2 3 4 4 4 4 4 1 1 2 3
# output: 1 2 3 4 4 3 1 1 0 2 3Since I expected that the long runs of zeroes would have length greater than 255, I also had alternate encoders that used LEB128 variable-length integer encoding.
Testing these four compressors over Donkey Kong running for 4000 frames (and using zlib compression as a baseline) gives the following results:
| Compressor | Size/Frame | Size/Sec | Compression Ratio |
|---|---|---|---|
| RLE1 | 11.8KiB | 704KiB/sec | 23.6% |
| RLE1 (LEB128) | 11.5KiB | 687KiB/sec | 23.0% |
| RLE2 | 7.3KiB | 436KiB/sec | 14.6% |
| RLE2 (LEB128) | 6.8KiB | 406KiB/sec | 13.7% |
| zlib | 3.9KiB | 232KiB/sec | 7.8% |
Step 2.4: Compressing Intermediate Frames
The zlib size is pretty good, but I figured I could do better taking into account the similarity between frames, similar to a video codec. If I store the per-byte difference between the current frame and a previous frame, then compress that, then the regions that didn't change will have long runs of zero.
The only thing to decide is how often to store base frames. I started with storing a base frame every 120 frames (~2 seconds), and compressing this difference with the same compressor. Since using LEB128 was always better, I only tested those. This gives the following results:
| Compressor | Size/Frame | Size/Sec | Compression Ratio |
|---|---|---|---|
| RLE1 (LEB128) | 1.01KiB | 60.4KiB/sec | 2.03% |
| RLE2 (LEB128) | 712bytes | 41.5KiB/sec | 1.39% |
| zlib | 597bytes | 34.8KiB/sec | 1.17% |
A 10x improvement for RLE!!
What was interesting to me about this is the difference between RLE2 and zlib: it turns out that even though the compression of zlib is much better for base frames, it isn't much better for the intermediate frames.
Since I showed that, at least for Donkey Kong, I could get 41.5KiB/sec for the first 4000 frames (~67 sec) of play, I decided it was time to start on the real implementation.
Step 2.5: Storing the Base and Intermediate Frames
The simplest way to store the base and intermediate frames is to store pointers to the data in a struct, then have a dynamic array of that struct. The only operations I need to implement are append and lookup, and I know that append happens a lot (once per frame), and lookup happens rarely (only during a rewind.)
But I didn't want to do this, since memory would grow unbounded. It's not too bad, but even at 41.5KiB/sec, that means 145MiB/hour which is OK for desktop but pretty big for a web app.
What I really wanted was a circular buffer, but also be able to lookup in the circular buffer in sublinear time. It is possible to perform a binary search on a circular buffer, but only with a fixed-size element.
But in my case, since the base and intermediate frames are compressed, they
will have different sizes. Even if I store the frames in sorted order, I won't
be able to binary search since I wouldn't be able to find the middle element.
But what if I separate each element into two parts: a fixed-size part
(RewindInfo) and a variable-size part (RewindData)?
typedef u8* RewindData;
typedef enum {
RewindInfoKind_Base,
RewindInfoKind_Diff,
} RewindInfoKind;
typedef struct {
Cycles cycles;
RewindData data;
size_t size;
RewindInfoKind kind;
} RewindInfo;Since I only have two kinds of elements in the buffer, I can use an old trick
to store them in the same buffer: RewindData grows from one end of the buffer
and RewindInfo grows from the other end.
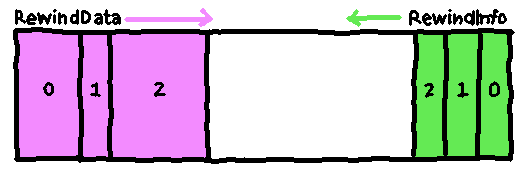
Since the RewindData is variable-size, it's easier if I have it grow
normally, from low to high addresses. Otherwise I'd have to write the
compressed data backward, or somehow guess how big the compressed buffer will
be. So the RewindInfo will grow backward, from high addresses to low
addresses.
Step 2.6: Handling Buffer Overflow
A normal circular buffer will wrap around and overwrite previous values when the buffer overflows. That happens with this buffer too, with some subtle differences.
First off, there are two times when the buffer overflows: when writing the
RewindInfo and when writing the RewindData. Ultimately, it doesn't really
matter which write fails since they both must be successful to continue. If
either fails, then I need to wrap around to the beginning to write the next
info/data pair. When this pair is written, it will overwrite a previously
written RewindInfo and RewindData. The RewindInfo is fixed-size, so it
can be overwritten without any further work. But the RewindData is
variable-size so there are three cases to consider: when the new data's size is
less than, equal, or greater than the old data's size.
The trivial case is when the sizes are equal and no further work needs to be
done. If the new data's size is smaller, a gap of unused data, equal to the
difference in size between the old and new data, will now exist. This doesn't
really matter though, because I never access the data directly, only through a
pointer in the RewindInfo struct.
If the new data size is larger than the old data size, then writing the new
data will likely overwrite data from the following RewindInfo structs. (It's
not guaranteed since, as mentioned above, there may be a gap of unused data
after.) When this happens, those RewindInfo structs are now invalid, so they
must be removed. Therefore there is now a gap of unused data in the
RewindInfo list.
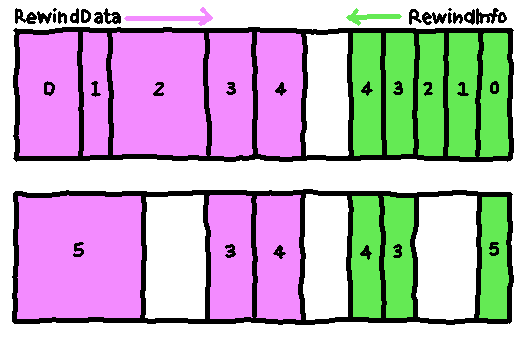
There are a few ways to solve this, but I believe the simplest is to split the
RewindInfo and RewindData areas of the buffer into two ranges:
typedef struct {
u8* begin;
u8* end;
} RewindDataRange;
typedef struct {
RewindInfo* begin;
RewindInfo* end;
} RewindInfoRange;
typedef struct {
RewindDataRange data_range[2];
RewindInfoRange info_range[2];
...
} RewindBuffer;The ranges are always ordered as follows:
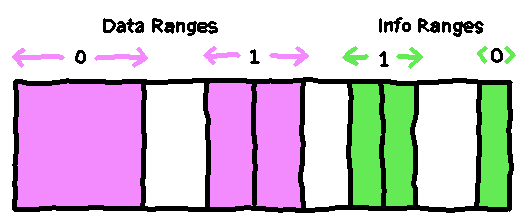
The data pointers in info_range[i] always point into data_range[i], where
i is either 0 or 1.
New RewindInfo is always added to the beginning of info_range[0], possibly
overwriting RewindInfo at then end of info_range[1]. Similarly, new
RewindData is always added to the end of data_range[0]. At the start,
data_range[1] and info_range[1] are empty, so prepending to info_range[0]
and appending to data_range[0] will just push the empty ranges toward the
center of the buffer:
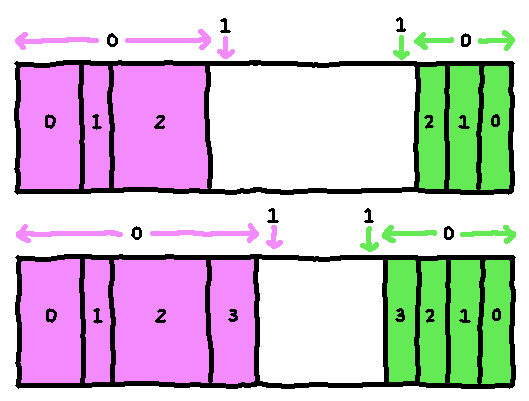
When the buffer is full, info_range[0] and data_range[0] are copied into
info_range[1] and data_range[1]. The underlying data in the buffer doesn't
change, just the members of the Range structs. Then info_range[0] and
data_range[0] are reset to empty ranges at the end and beginning of the
buffer, respectively.
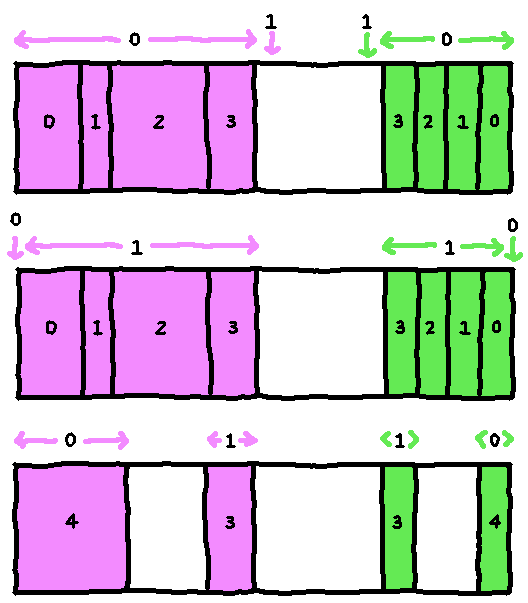
As before, RewindInfo and RewindData is written to the beginning
info_range[0] and end of data_range[0]. But now they may also overwrite
info_range[1] and data_range[1]. When this happens, those ranges are
shrunk, making sure this invariant is kept:
info_range[1].end[-1].data == data_range[1].beginHere's an animation of the first 20 seconds of Donkey Kong, using a 128KiB
buffer. The lighter colors are used for range 0 and the darker colors for
range 1.

There's some additional subtlety required (choosing intermediate vs. base states, keeping an uncompressed copy of the last base state, etc.) but this covers the most important parts of the rewind buffer data structure. Once I had written this, I was almost done. Just needed to write the rewinding code. So of course I stopped working on it for a few months.
Step 3: Rewinding
When I came back to working on binjgb, I was determined to finish the rewind feature. At this point, I had enough information to do exactly what nintaco did:
For random access, it restores the nearest save state and then it uses the input sequence to fill in the gap.
So, to rewind to a given cycle count cycle, do the following:
- If
cycle<info_range[1].end[-1].cycle, then thiscycleis too old; error. - Determine which
info_rangecontainscycle. Note that thecyclemay be newer than the most recent saved state; in that case, useinfo_range[0]. - Binary search the range (which is guaranteed to have at least one element),
assign the result to
found. - If
foundis a base state:- Decompress the data in
found->data. - Load the decompressed save state.
- Decompress the data in
- Else,
foundmust be an intermediate state:- Find the previous base state by searching backward through the range,
assigning the result to
base. - If it is not found and the range is
info_range[0]:- Search through
info_range[1], assign the result tobase.
- Search through
- If
baseis was not found; error. - Decompress the base state data in
base->data. - Decompress the intermediate data in
found->data, adding each decompressed byte to the byte at the same index in the base state. - Load the decompressed save state.
- Find the previous base state by searching backward through the range,
assigning the result to
- Find the joypad data for the current cycle count (which just changed because we loaded a save state).
- Run the emulator forward until
cycle, starting from the joypad data found in the previous step.
The final step is to remove any states after found. This is necesary to
prevent rewinding to an invalid state. As soon as the player continues playing,
new data will be written to the rewind buffer. These new states represent a
parallel universe -- a fork in the timeline. Appending these would mean that
time is no longer linear and ordered in the buffer, so binary search won't
work.
I separated the final step out into another function so I can support a rewind
mode in the debugger. This way, you can call host_begin_rewind and seek
through all previous save states. When you find the state you want to rewind
to, you can call host_end_rewind and continue playing.
You can see some of the final rewind buffer stats at the bottom of this video. The rate during gameplay is closer to 70KiB/sec instead of 40KiB/sec I calculated above, but I'm still pretty happy with the result.
Step 4: Enjoy!!
Once I had rewind working, I wired it up to a hotkey and just started playing, rewinding away my many mistakes.
😄
I really wanted to finish this post before the end of the year, and it seems like I just made it (in my time zone anyway.)
Happy New Year everyone!